


Table of contents
- Why exactly once delivery matter?
- What problem does exactly once delivery solve?
- What benefit does it provide a developer compared to other paradigms?
- Why is guaranteed-once delivery challenging to achieve?
- Kafka
- Exactly once conceptual in Kafka
- Idempotence: Exactly once in order semantics per partition
- Transactions: Atomic writes across multiple partitions
- Exactly-once guarantees in Kafka: Design, built, and performance
- How Kafka works
- Kafka performance
- Nats
- NATS client applications
- HarperDB
- HarperDB client applications
- Which system best works for real-time data processing?
- What makes NATS superior?
- Conclusion
Why exactly once delivery matter?
In order for the end-to-end systems to function as if just one message was ever sent, exactly once processing allows duplicate messages to be sent over the network as long as they are identical, and duplications are found and removed from the consuming system.
As a result, the application developer may rely on the middleware to handle the cleanup logic instead of having to implement it in every one of their apps.
What problem does exactly once delivery solve?
Exactly once delivery ensures that the communication won't be lost or delivered twice, and the side effects will only be experienced once.
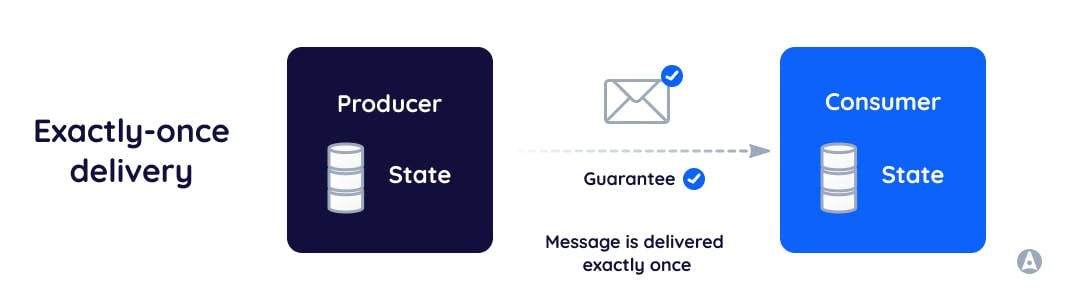
Guaranteed Once-delivery or Exactly-once is a guarantee that once acknowledged, a message published to the platform is delivered directly to end-user devices in real-time, even when individual system components fail.
Although exactly once is a popular and desirable message delivery guarantee, it's a remarkably complex engineering challenge to solve and deliver.
Guaranteed delivery means a message can be delivered to a recipient only once. While a message delivered only once by a recipient is the norm, it is impossible to guarantee it.
The system will typically deliver messages just once (in the absence of logic bugs).
However, when an error happens in the design, it can happen in 2 ways, at most once delivery or at least once delivery.
When a message is only sent once, it either doesn't reach the recipient or, if it does, it is lost before the recipient's state changes, leaving it in a condition identical to it was before the event was received.
“At-least-once” delivery- A message gets delivered more than once. guarantee.
What benefit does it provide a developer compared to other paradigms?
Large financial institutions (LinkedIn, FB, Netflix, GE, Bank OF America, Fannie Mae, Chase Bank, etc.), as well as unicorn startups, IoT, the health sector, and other industries, use Kafka.
In comparison to Kafka, NATS has a fairly tiny infrastructure; Compared to NATS, Kafka is more developed and handles large data streams very well. Due to its emphasis on a more limited range of use cases, NATS Server only offers a subset of Kafka's functionality.
NATS was created for "fire and forget" scenarios, in which high performance and low latency are essential, but losing some data is acceptable if necessary to keep up with data. Architecturally, this is due to NATS' lack of a persistence layer for long-term data storage.
Why is guaranteed-once delivery challenging to achieve?
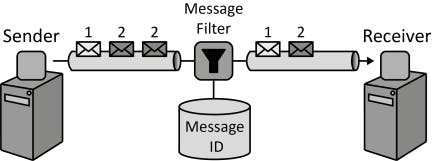
Exactly once is a system-wide property and is only possible to achieve with all the constituent components playing their part effectively and efficiently.
Today, streams of data records, including events, are continuously produced by many information sources.
A streaming platform enables developers to create applications that continually receive and analyze these streams with a high degree of authenticity and accuracy.
It also provides options for applications to respond to data or events in real-time, depending on the exact order of their occurrence, at a breakneck speed
In this article, let's discuss three tools for ensuring Exactly Once Delivery:
- Kafka
- HarperDB
- NATS
Kafka
Kafka offers the following types of message delivery guarantees.
At-most once guarantees: Every message carries on in Kafka at-most-once. Message loss is possible in case of the producer not retrying on failures.
At least once guarantee: Every message will be persisted in Kafka at least once. While there is no chance of message loss, message duplication is possible if the producer retries when the message has already persisted.
Exactly once guarantee: Every message will persist in Kafka without duplication or data loss, even if a broker failure or producer retry occurs.
How Kafka supports Exactly Once Processing with the Producer, Consumer, and Broker components working together to achieve Exactly Once Guarantee?
Exactly once conceptual in Kafka
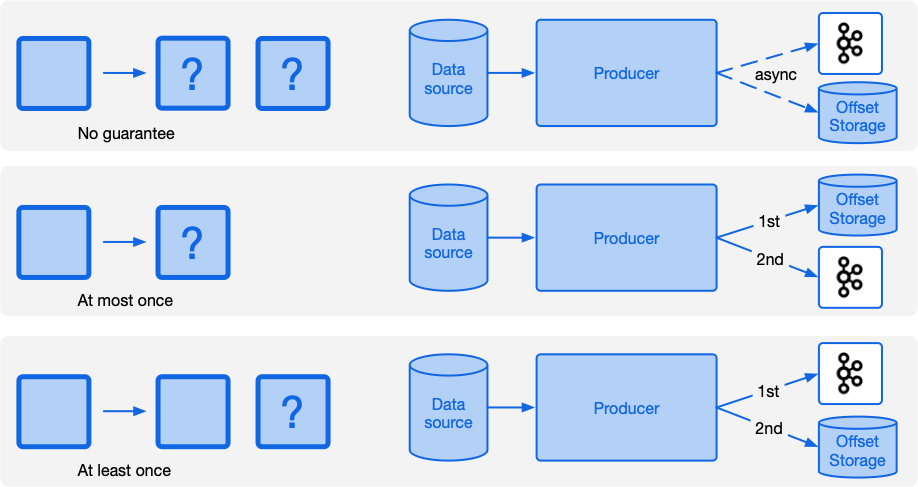
In the new exactly once semantics feature, Kafka’s software processing semantics is strengthened in 3 different and interrelated ways.
Idempotence: Exactly once in order semantics per partition
Idempotent operations allow for repeated execution without altering the outcome from a single execution.
The producer send operation is now idempotent. In the event of an error that would cause a producer to retry, the same message (still sent by the producer multiple times) will only be written to the Kafka log on the broker once.
The Idempotent producer transmits the risk of duplicate messages resulting from producer or broker faults for a single partition.
Transactions: Atomic writes across multiple partitions
With the new version, Kafka now supports atomic writes across multiple partitions via a new transactions API.
It enables a producer to send a batch of messages to multiple partitions so that either all or none of the messages in the batch are ever visible to consumers.
You can also commit your consumer offsets in the same transaction as the data you've processed, allowing for end-to-end exactly once semantics.
Exactly-once guarantees in Kafka: Design, built, and performance
It is an open-source, distributed streaming platform that enables applications to rapidly publish, consume, and process large volumes of record streams.
It can ingest and process trillions of records per day without any perceptible performance lag as volumes scale.
Kafka is currently the most widely used streaming platform. Fortune 500 companies such as Target, Microsoft, Airbnb, and Netflix rely on it to deliver a real-time, data-driven experience to their customers.
How Kafka works
Kafka's three main qualities are as follows:
- Applications can now subscribe or broadcast data or event streams
- Reliable and durable record saving in a precise, sequential manner.
- Real-time record processing (as they occur).
Kafka performance
Kafka is a distributed platform operating as a fault-tolerant, highly available cluster spanning multiple servers and data centres.
Kafka topics are partitioned and replicated to scale to serve many concurrent users without encountering performance issues.
Pros of Apache Kafka
Timely message consumption: With a response time of up to 10 milliseconds, Kafka enables timely message consumption by the user due to the message's decoupling.
High Throughput: With its low latency, Kafka can process more high-volume, high-velocity communications and can handle thousands of messages in a single second.
Resistant to node/machine failure inside the cluster thanks to the fault tolerance feature.
Durability: The durable Replication feature allows data or messages to retain more on a cluster than a disc, reducing the demand for numerous integrations.
With an automatic interface, all producing and consuming systems are sorted and just need to build one integration with it.
Real-time data pipeline Kafka has the capability for handling real-time data utilizing Processors, analytics, and storage, along with other components.
Kafka employs use cases resembling a batch process. It can also serve as an ETL tool due to its capacity for data persistence.
Expandability: Kafka is an expandable software solution due to its capacity to handle several messages at once.
Cons with Apache Kafka
Incomplete set of management and monitoring tools translating to hesitancy from new businesses or startups to deal with Kafka.
Problems with message modification: Kafka uses system calls for sending messages to the consumer. This means a diminished performance if the message needs adjustment.
Performance de-escalation: Data flow compressing and decompressing impacting both its throughput and performance.
When the Kafka Cluster's queue count increases, Apache Kafka commonly displays uncoordinated behaviour.
Nats

NATS is a simple, secure, and connective technology designed for today's hyper-connected world. It is a unified technology that enables secure application communication across cloud vendors, on-premise, edge, web and mobile, and devices.
It's an infrastructure that fulfils data exchange needs for software applications and services, segmented in the form of messages or "message-oriented middleware."
It allows application developers to
- Effortlessly build distributed and scalable client-server applications.
- Data storage and distribution in real-time, achieved across various environments, languages, cloud providers, and on-premises systems.
The primary platform for developing distributed applications is the NATS Server, which offers Client APIs in over 40 different programming languages and frameworks, including Go, Java, JavaScript/TypeScript, Python, Ruby, Rust, C#, and NGINX.
JetStream platform is built into the NATS server supporting Real-time data streaming, highly resilient data storage, and flexible data retrieval.
NATS is now being implemented by some of the biggest cloud platforms, such as VMware, Cloud Foundry, Baidu, Siemens, and GE.
Core NATS provides "at-most-once" delivery, which means that messages are assured to show up intact and in order from a single publisher, but not across multiple publishers. It does everything required to remain available and provide a dial tone. However, it's important to keep in mind that the basic Because the NATS platform is a basic pub-sub transport system with only TCP reliability. If a subscriber has issues or is offline, it won't receive messages.
NATS client applications
NATS has a tightly integrated family of open-source products that can be deployed easily and independently.
This technology is being used globally by thousands of companies, spanning use cases including micro services, edge computing, mobile, and IoT, and can be used to augment or replace traditional messaging.
A developer can use one of the NATS client libraries to publish, subscribe, request, and reply between instances of the client applications or between completely separate applications.
Pros of NATS
Embeddable. NATS server embeds into your Go binary so there's no need to run it separately.
Auto-discovery. Makes it possible to discover routes to other servers making clustering a breeze. Combining auto-discovery with an embedded server, a pretty good mesh network between your nodes can be achieved.
Straightforward pub/sub. With NATS, pub/sub functionality is as simple as deciding on the topic you want to publish to and just carrying that out. With no additional steps required to confirm that specific topics and subscribers exist before dispatching payloads, our system is substantially simpler.
- Optional persistence, The NATS server provides the ability to persist messages to ensure delivery. Because this capability is optional, the NATS server will be lighter for users like Storages who don't require it, which is advantageous for all parties.
Cons of NATS
Lack of proper authentication. The current authentication method doesn't have the option to dynamically add/remove users to the NATS server. It's a useful feature for users who would want to distribute client applications that connect to the main server via the NATS protocol. It is not intended for end-users.
Shallow context integration. A recent function is added by NATS to make a request with context, but it only stops waiting for a response.
HarperDB
Behind the scenes, HarperDB uses NATS to manage node-to-node data replication. Essentially creating an easy-to-tailor real-time distributed database without the middleware. By utilising a database that natively manages replication, developers simply have less to juggle.
This allows discrete nodes, no matter where they are, to publish data to a stream while other nodes subscribe to the stream. Further, HarperDB takes advantage of NATS Jetstream to guarantee exactly-once delivery to all subscribed nodes, even in the face of spotty network connections.
However, the advantages of HarperDB go well beyond replication. In the HarperDB more-than-a-database paradigm, aka Custom Functions.User-defined applications on each node can process data locally in real-time and place relevant event/alert data onto designated tables that others can subscribe to, allowing central stores to have a smaller footprint and utilize less RAM.
The receiving node that subscribes to multiple tables can even have a separate user-defined application designed to process data from multiple sources.
HarperDB is unique in the world of exactly-once delivery since it's not just a delivery system but a whole development platform that manages the database, application, and replication of a distributed system.
HarperDB is the first distributed database with a combination of SQL and NoSQL functionality and a REST API.
The HarperDB platform is developed with characteristics such as global data replication in under 100ms, with a response time of milliseconds, and integrating API and database functions into a single product to support APIs, AI/ML, edge computing, and integration.
HarperDB supports multiple programming languages and can be deployed anywhere (local, edge, and/or cloud).
With an intuitive REST API, the HarperDB database supports key values, document stores, and both SQL and NoSQL.
HarperDB, which is designed for speed and simplicity of use, enables users to gather, process, and distribute data across their company from the edge, on-premises, and into the cloud.
HarperDB client applications
With custom functions, users can get the API and database on the same platform - HarperDB is ideal for low latency & distributed compute use cases in the Gaming industry, Media, & Government.
Organizations use HarperDB to extend their current functionality, keep their existing database system(s) in place, and oftentimes for a different capability altogether.
It is an excellent system that effectively streamlines data collection, timely delivery, analysis, and action based on the proper data, among other things.
Which system best works for real-time data processing?
KAFKA- Real-time streaming data pipelines
Building applications that can adapt to data streams and real-time streaming data pipelines are particularly well suited to Kafka. To enable the analysis and storage of both past and real-time data, it mixes transmission, storage, and stream processing.
What makes NATS superior?
NATS-Messages & Communications
Advantages of NATS-Over other messaging queues, NATS provides a number of significant advantages. It skillfully mixes three significant communications methods into a single library.
Asynchronous pub/sub ensures broadcasting to all; that's excellent when you need to inform your cluster about certain changes. When we need to adjust the volume settings and notify the entire cluster, we use it during volume provisioning. Any node can access any volume in the cluster through our "virtual volumes," which are configured by NATS and have a global namespace for volume access.
Asynchronous pub/sub queues deliver one message to the first subscriber in the queue, which works perfectly when you want only one worker to get the message as it is. For Organizations that have hundreds of workers that constantly dequeue messages, this feature removes some of the need for locking/orchestration code.
Synchronous requests- At times, a function making a request to another node needs to know right away whether that node succeeded or failed to process the message, which is where Publish Request comes in. The core scheduler of StorageOS primarily uses requests, orchestrating and providing volumes in the cluster. It needs to know whether the request to a node where the master volume is going to be deployed or not. If it's not deployed, there is no point in configuring replicas or virtual volumes.
Conclusion
In a distributed system, the system checks for a receipt acknowledgement to ensure that a message is delivered, but a lot can go wrong.
It's critical to understand that distributed systems are primarily governed by trade-offs like client (browser) versus server.
- Distributed, Server and database?
- Distributed Server and message queue?
Distributed We cannot have exactly-once message delivery in the Distributed System without the assistance of other software(s).
The three tools mentioned above, each with their own distinct features, contribute to the possibility of Once guaranteed delivery.
That’s it for today & Thanks for reading.
If you enjoyed this article, you'll like my newsletter:
Join here: 2-1-1 Career Growth Newsletter